这道java编程题谁会写?importjava.util.Scanner;
publicclassMain{publicstaticvoidmain(String[]args){//从键盘上输出一个字符串,假定字符串的长度小于80,将该串中出现的所
kettle转换
软件
2023-02-24
如何给一个 Kettle 转换设置变量和命令行参数
1. 变量的类型 Kettle 的早期版本中的变量只有系统环境变量 目前版本中(3.1) 变量包括系统环境变量, "Kettle变量" 和内部变量三种系统环境变量的影响范围很广,凡是在一个 JVM下运行的线程都受其影响.Kettle 变量限制了变量的作用范围, 变量范围包括三种分别是 grand-parent job, parent job, root job 内部变量: 是 kettle 内置的一些变量, 主要是kettle 运行时依赖的环境, 如转换文件名称, 转换路径,ip地址, kettle 版本号等等.2. 变量的设置 "系统环境变量" 有三种设置方式 1) 通过命令行 -D 参数kettle教程是什么?
kettle 是纯 java 开发,开源的 ETL工具,用于数据库间的数据迁移 。可以在 Linux、windows、unix 中运行。有图形界面,也有命令脚本还可以二次开发。
kettle 的官网是https://community.hitachivantara.com/docs/DOC-1009855,github地址是https://github.com/pentaho/pentaho-kettle。
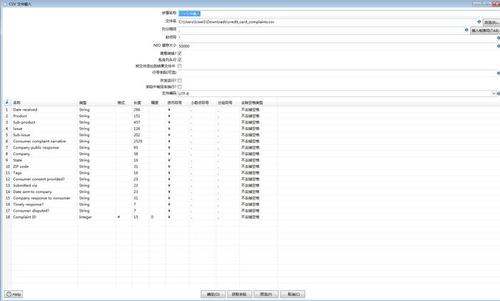
安装。
这边以 windows 下的配置为例,linux 下配置类似。
jdk 安装及配置环境变量。
由于 kettle 是基于 java 的,因此需要安装 java 环境,并配置 JAVA_HOME 环境变量。
建议安装 JDK1.8 及以上,7.0以后版本的 kettle 不支持低版本 JDK。
下载 kettle。
从 官网 下载 kettle ,解压到本地即可。
下载相应的数据库驱动。
由于 kettle 需要连接数据库,因此需要下载对应的数据库驱动。
例如 MySQL 数据库需要下载 mysql-connector-java.jar,oracle 数据库需要下载 ojdbc.jar。下载完成后,将 jar 放入 kettle 解压后路径的 lib 文件夹中即可。
注意:本文基于 pdi-ce-7.0.0.0-25 版本进行介绍,低版本可能有区别。
启动。
双击 Spoon.bat 就能启动 kettle 。
转换。
转换包括一个或多个步骤,步骤之间通过跳(hop)来连接。跳定义了一个单向通道,允许数据从一个步骤流向另一个步骤。在Kettle中,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。
1、打开 kettle,点击 文件->新建->转换。
2、在左边 DB 连接处点击新建。
3、根据提示配置数据库,配置完成后可以点击测试进行验证,这边以 MySQL 为例。
4、在左侧找到表输入(核心对象->输入->表输入),拖到右方。
5、双击右侧表输入,进行配置,选择数据源,并输入 SQL。可以点击预览进行预览数据。
6、在左侧找到插入/更新(核心对象->输出->插入/更新),拖到右方。
7、按住 Shift 键,把表输入和插入/更新用线连接起来。
8、双击插入/更新进行配置。
9、点击运行,就可以运行这一个转换。
10、运行结束后,我们可以在下方看到运行结果,其中有日志,数据预览等,我们可以看到一共读取了多少条数据,插入更新了多少数据等等。
这样就完成了一个最简单的转换,从一个表取数据,插入更新到另一个表。
作业。
如果想要定时运行这个转换,那么就要用到作业。
1、新建一个作业。
2、从左侧依次拖动 START 、转换、成功到右侧,并用线连接起来。
3、双击 START,可以配置作业的运行间隔,这边配置了每小时运行一次。
4、双击转换,选择之前新建的那个转换。
5、点击运行,就能运行这次作业,点击停止就能停止。在下方执行结果,可以看到运行的日志。
这样就完成了一个最简单的作业,每隔1小时,将源表的数据迁移到目标表。
总结:kettle 是一个非常强大的 ETL 工具,通过图形化界面的配置,可以实现数据迁移,并不用开发代码。
通过它的作业,kettle 能自动地运行转换。
kettle可以在同一个数据库里进行数据转换吗
在kettle常常有处理从一个源数据中做转换.做转换的时候, 需要去查另一个数据库. 这种问题遇到数据小时候还好办. 但是数据魇 时候就麻烦来了. 下面针对三种情况做具体情况的选择办法 先上一个图 [img] [/img] 1. 当需要转换的数据特别大的时候, 例如: 10W条以上.或者100W条以上时. 上图中,hadoop数据导入,导入的数据如果够多,例如100W条以上,其中一个字段需要查询数据库中查询,而这个字段的类型并不多,例如只有10个类型或者数据库中就只有这10个类型.那么,可以走线路2, 并且线路2中的 "使用缓存" 可以打勾,也可以不打.当然你这个源里的数据太多,打上当然最好了Kettle中的转换里面的设置变量的作用是什么
方便你在之后或者子项目中获取到你设置的变量。
比如你在这里设置了一个变量名叫FIELD,你在之后的转换“表输入”控件里SQL可以这么写

设置变量大多用在在循环或者某个字段容易变化的时候,方便之后取到这个值
谢谢采纳
kettle 一个作业中多个转换时顺序执行的吗
start后面的连接线是“锁型”表示无条件执行 转换 后的是“对勾”表示执行成功后执行下一个 如上图“转换”执行成功后才会执行“转换2”,如果出错,整个JOB就停止了相关文章
-
编程题谁会!!!!详细阅读

-
MATLAB抽样编程详细阅读

matlab 音频采样怎么实现 高手进在进行通讯和DSP等试验过程中,信号源是不可缺少的一个工具,很多设备是使用信号源来模拟检测实际目标,来验证设备的功能及可靠性。通常,对于研制
- 详细阅读
-
怎样用VAB编程,实现按键保存功能详细阅读

excel如何制作一个vba按钮,点一下之后让sheet1里面的部份数据,自动保存到sheet2里面?如果菜单栏没有“开发工具”选项卡,右击上方菜单栏空白处——自定义功能区,选中“开发工具”
-
编程问题求五边形面积详细阅读

编程根据五边形五个顶点的坐标计算五边形面积,请用C++面向程序设计,并且是函数做的五个顶点依次是1,2,3,4,5 三角形123三边12,23,13为a,b,c则s=(a+b+c)/2,面积S=根号下(s(s-a)(s
-
用c语言编程代码详细阅读

求简单C语言程序代码!输入2个正整数m和n,求其最大公约数和最小公倍数#include#includeint main()int m,n,p,q,s,r;printf("请输入两个正整数;m,n\n");scanf("%d,%d",&m,&n);#in
-
c++编程问题详细阅读

c语言编程问题#include #include
struct student {int num;char name[20];float score[4];};
void input(struct student a[], int);
void aver(struct student a[], int,s -
用C语言编程实现,任意输入年,输出该详细阅读

c语言设计万年历 输入任意年份,输出该年12个月份 输入任意年份月份,输出该年月日历程序直接输入年份和月份,打印对应日历。一年12个月是固定的,我就不写单独输入年份打印月份了
-
A++这个编程语言好不好学?详细阅读

A++这个编程语言好不好学?好学好学,很好学的。我想自学编程,好学吗?编程当然可以自学。自学编程大约需要两三个月,每天抽出两三个星期把基础全部学习一遍,其他都是建立在基础之上
-
三菱3U机用步进SFC块编程红绿灯详细阅读

三菱FX系列PLC怎么编写SFC程序块,自动,急停,手动,如何启动与停止这些块。FX系列里有个方便指令叫 IST 可以编写手动,回原点,单步运行,单周期运行,全自动运行,回原点启动,自动运
