
学计算机技术有用吗?当然有用, 认真学,专一门,软件或者硬件。 软件方面比较有前途的是:网页制作开发、软件开发(编程)、平面设计、三维设计; 硬件方面主要是维修、组装,在硬件方面学
Vector是如何创建兼容不同类型的变量
软件
2023-05-18
JAVA一个向量(vector)对象中可以存放不同类型的对象?
Vector是一个泛型类,如果不为类型变量指定一个类型或将类型变量的值指定为Object,则可以用Vector类的对象来存放不同类型的对象。C++的vector可以混编不同类型的元素么?比如0是数字,…5412
vector里面的元素必须是同类型的,继承关系也可以.vector c++ 用法是什么?
c++中,vector作为容器,它的作用是:用来存放结构体struct类型的变量。以下是vector的具体用法:
工具/材料:电脑、c++编译器
1、首先,打开c++编译器,构造一个int类型的空vector向量。
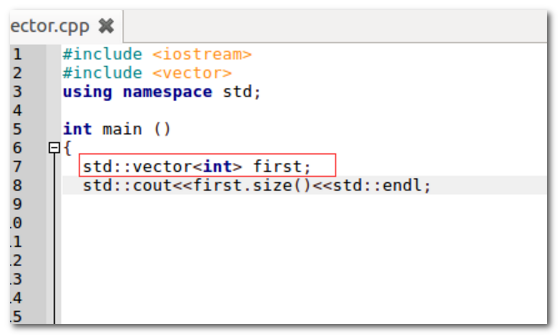
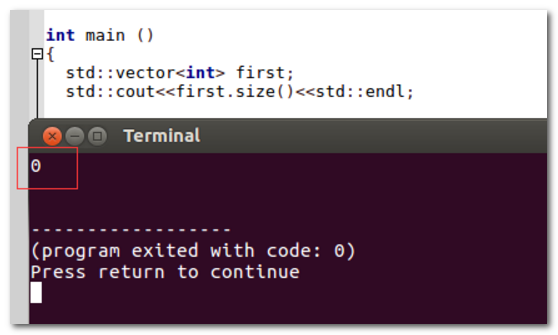
2、程序运行结果如图,可以看到vector的size为0。
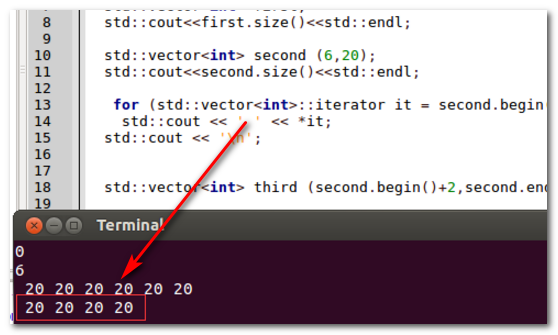
3、如红框勾选所示,构造了6个元素值为20的vector向量。
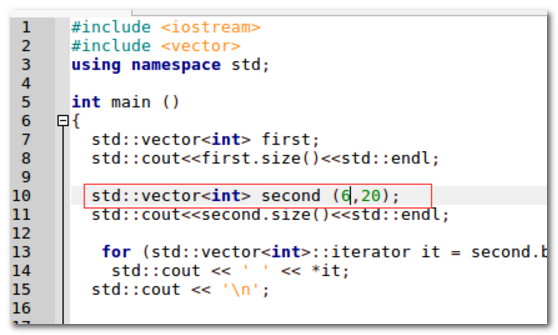
4、运行结果显示,成功的构造了6个元素为20的向量。
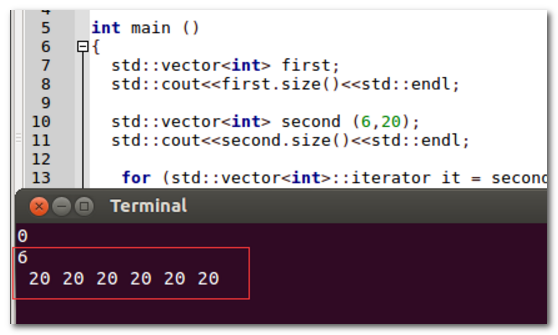
5、以现有vector对象的范围作为构造函数的参数,同样也将对象复制给另一个vector对象。

6、以下,就是程序运行结果了。
基本函数实现
1、构造函数
vector():创建一个空vector
vector(int nSize):创建一个vector,元素个数为nSize
vector(int nSize,const t& t):创建一个vector,元素个数为nSize,且值均为t
vector(const vector&):复制构造函数
vector(begin,end):复制[begin,end)区间内另一个数组的元素到vector中
2、增加函数
void push_back(const T& x):向量尾部增加一个元素X
iterator insert(iterator it,const T& x):向量中迭代器指向元素前增加一个元素x
iterator insert(iterator it,int n,const T& x):向量中迭代器指向元素前增加n个相同的元素x
iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
实例:
#include
int main(){
vector
for(int i=0;i<10;i++) // push_back(elem)在数组最后添加数据
{
obj.push_back(i); cout<
for(int i=0;i<5;i++)//去掉数组最后一个数据
{
obj.pop_back(); }
cout<<"\n"<
cout<
return 0;}
vector泛型支持的类型
java vector 泛型_java中关于泛型的小结 原创 2021-03-07 00:46:47 蓝宝王 码龄4年 关注 ------------------------------------------------------------ 泛型入门 1 jdk1.5以前的集合中存在的问题 ArrayList collection=new ArrayList(); collection.add(1); collection.add(1L); collection.add("abc"); int i=(Integer)arrayList.get(1);//编译要强制类型转换且运行时出错!vector的详细说明
vector 是同一种类型的对象的集合,每个对象都有一个对应的整数索引值 。
和 string 对象一样,标准库将负责管理与存储元素相关的内存。我们把 vector称为容器,是因为它可以包含其他对象,能够存放任意类型的动态数组,增加和压缩数据。一个容器中的所有对象都必须是同一种类型的 。
vector 是一个类模板(class template)。使用模板可以编写一个类定义或函数定义,而用于多个不同的数据类型。因此,我们可以定义保存 string 对象的 vector,或保存 int 值的 vector,又或是保存自定义的类类型对象(如Sales_items 对象)的 vector。vector 不是一种数据类型,而只是一个类模板,可用来定义任意多种数据类型。vector 类型的每一种都指定了其保存元素的类型 。
为了可以使用vector,必须在你的头文件中包含下面的代码:
#include
vector属于std命名域的,因此需要通过命名限定,如下完成你的代码:
using std::vector;
vector
或者连在一起,使用全名:
std::vector
建议在代码量不大,并且使用的命名空间不多的情况下,使用全局的命名域方式:using namespace std;
函数
表述
c.assign(beg,end) c.assign(n,elem)
将(beg; end)区间中的数据赋值给c。将n个elem的拷贝赋值给c。
传回索引idx所指的数据,如果idx越界,抛出out_of_range。
c.back()
传回最后一个数据,不检查这个数据是否存在。
c.begin()
传回迭代器中的第一个数据地址。
c.capacity()
返回容器当前已分配的容量。
c.clear()
移除容器中所有数据。
c.empty()
判断容器是否为空。
c.end() //指向迭代器中末端元素的下一个,指向一个不存在元素。
c.erase(pos)// 删除pos位置的数据,传回下一个数据的位置。
c.erase(beg,end)
删除[beg,end)区间的数据,传回下一个数据的位置。
c.front()
传回第一个数据。
get_allocator
使用构造函数返回一个拷贝。
c.insert(c.begin()+pos,elem)//在pos位置插入一个elem拷贝,传回新数据位置
c.insert(c.begin()+pos,n,elem)//在pos位置插入n个elem数据,无返回值
c.insert(c.begin()+pos,beg,end)//在pos位置插入在[beg,end)区间的数据。无返回值
c.max_size()
返回容器中最大数据的数量。
c.pop_back()
删除最后一个数据。
c.push_back(elem)
在尾部加入一个数据。
c.rbegin()
传回一个逆向队列的第一个数据。
c.rend()
传回一个逆向队列的最后一个数据的下一个位置。
c.resize(num)
重新指定队列的长度。
c.reserve()
保留适当的容量。
c.size()
返回容器中实际数据的个数。
c1.swap(c2)//将c1和c2元素互换
swap(c1,c2)//同上操作。
vector
vector
vector
vector
vector
c.~ vector
operator[]
返回容器中指定位置的一个引用。
创建一个vector
vector容器提供了多种创建方法,下面介绍几种常用的。
创建一个Widget类型的空的vector对象:
vector
创建一个包含500个Widget类型数据的vector:
vector
创建一个包含500个Widget类型数据的vector,并且都初始化为0:
vector
创建一个Widget的拷贝:
vector
向vector添加一个数据
vector添加数据的缺省方法是push_back()。push_back()函数表示将数据添加到vector的尾部,并按需要来分配内存。例如:向vector
for(int i= 0;i<10; i++) {
vWidgets.push_back(Widget(i));
}
获取vector中指定位置的数据
vector里面的数据是动态分配的,使用push_back()的一系列分配空间常常决定于文件或一些数据源。如果想知道vector是否为空,可以使用empty(),空返回true,否则返回false。获取vector的大小,可以使用size()。例如,如果想获取一个vector v的大小,但不知道它是否为空,或者已经包含了数据,如果为空时想设置为 -1,你可以使用下面的代码实现:
int nSize = v.empty() ? -1 : static_cast
访问vector中的数据
使用两种方法来访问vector。
1、 vector::at()
2、 vector::operator[]
operator[]主要是为了与C语言进行兼容。它可以像C语言数组一样操作。但at()是我们的首选,因为at()进行了边界检查,如果访问超过了vector的范围,将抛出一个例外。由于operator[]容易造成一些错误,所以我们很少用它.
删除vector中的数据
vector能够非常容易地添加数据,也能很方便地取出数据,同样vector提供了erase(),pop_back(),clear()来删除数据,当删除数据时,应该知道要删除尾部的数据,或者是删除所有数据,还是个别的数据。
remove()算法 如果要使用remove,需要在头文件中包含如下代码:
#include
remove有三个参数:
1、 iterator _First:指向第一个数据的迭代指针。
2、 iterator _Last:指向最后一个数据的迭代指针。
3、 predicate _Pred:一个可以对迭代操作的条件函数。
条件函数
条件函数是一个按照用户定义的条件返回是或否的结果,是最基本的函数指针,或是一个函数对象。这个函数对象需要支持所有的函数调用操作,重载operator()()操作。remove是通过unary_function继承下来的,允许传递数据作为条件。
例如,假如想从一个vector
#include
enum findmodes {
FM_INVALID = 0,
FM_IS,
FM_STARTSWITH,
FM_ENDSWITH,
FM_CONTAINS
};
typedef struct tagFindStr {
UINT iMode;
CString szMatchStr;
} FindStr;
typedef FindStr* LPFINDSTR;
然后处理条件判断:
class FindMatchingString : public std::unary_function
public:
FindMatchingString(const LPFINDSTR lpFS) :
m_lpFS(lpFS) {
}
bool operator()(CString& szStringToCompare) const {
bool retVal = false;
switch (m_lpFS->iMode) {
case FM_IS: {
retVal = (szStringToCompare == m_lpFDD->szMatchStr);
break;
}
case FM_STARTSWITH: {
retVal = (szStringToCompare.Left(m_lpFDD->szMatchStr.GetLength())
== m_lpFDD->szWindowTitle);
break;
}
case FM_ENDSWITH: {
retVal = (szStringToCompare.Right(m_lpFDD->szMatchStr.GetLength())
== m_lpFDD->szMatchStr);
break;
}
case FM_CONTAINS: {
retVal = (szStringToCompare.Find(m_lpFDD->szMatchStr) != -1);
break;
}
}
return retVal;
}
private:
LPFINDSTR m_lpFS;
};
通过这个操作你可以从vector中有效地删除数据:
FindStr fs;
fs.iMode = FM_CONTAINS;
fs.szMatchStr = szRemove;
vs.erase(std::remove_if(vs.begin(),vs.end(),FindMatchingString(&fs)),vs.end());
Remove(),remove等所有的移出操作都是建立在一个迭代范围上的,不能操作容器中的数据。所以在使用remove,实际上操作的时容器里数据的上面的。
看到remove实际上是根据条件对迭代地址进行了修改,在数据的后面存在一些残余的数据,那些需要删除的数据。剩下的数据的位置可能不是原来的数据,但他们是不知道的。
调用erase()来删除那些残余的数据。注意上面例子中通过erase()删除remove的结果和vs.enc()范围的数据。
常见错误:
no matching function for call to ‘std::vector,一般由定义的类型与存入的类型不匹配引起。

相关文章
- 详细阅读
-
C语言编程作业,急详细阅读

c语言作业 急#include
int main(){ int a,b; scanf("%d%d",&a,&b); if(b!=0) printf("%d %d\n",a/b,a%b); else printf("error\n"); return 0;}C语言编程作业,求 -
慧编程如何启动游戏详细阅读

别人发过来的慧编程我怎么打开首先,打开慧编程软件界面后,鼠标点击右上角的Python编辑器按钮.等待模式加载完成后,点击左上角文件菜单下的新建作品按钮.接着,输入print ("Hello
- 详细阅读
-
你好 我想让孩子学编程 有没有好详细阅读

少儿编程应该如何入门,从哪里学比较好?少儿编程入门在童程童美学比较好。童程童美少儿编程体验课,点击可免费报名试听
童程童美在线课程采用分级模式,一二年级学生学习Scratch -
春草五轴抛光机怎么编程详细阅读

抛光实现报告没有找到完全匹配的,只能凑合着用,改改实际内容即可,格式可以借用。。。 资料一:生产见习报告: 五一期间,我到我舅舅那生产实习。他是个体工商户,是专业生产剑麻轮的商
-
从入行到cnc编程工程师需要经历什详细阅读

学CNC编程该从哪下手学起?初学编程的话软件要选好,选那边使用最多的编程软件,现在UG 用的势头比较好点。软件,先要熟练的使用,然后就是按部就班的跟着别人学吧。如果能够看懂图纸
-
单片机编程题不会?详细阅读
单片机编程题?振荡频率为6MHz,计时脉冲周期是2us,产生方波频率为2KHz, 周期500US,半个周期是250us,计数脉冲个数是125个,定时器方式2是8位定时器,最大计数值256,因此初值是256-125
-
如何把编程猫定制课的作品下载到电详细阅读
编程猫如何把编好的视频提取出来1、首先将编辑好的视频,按右键需要导出的角色,选择导出角色选项。
2、其次会生成一个编程猫的bcmp文件END1,在源码编辑器打开需要导入角色的作 -
数控编程求代码详细阅读

数控车床编程代码是什么?数控车床编程代码是G00快速定位指令,G01直线插补指令等。G00快速定位指令格式为G00XUZW,XZ为绝对编程时的目标点,UW为相对编程时的目标点,两轴同时以机床
