
python windows系统 源代码一、python如何运行程序首先说一下python解释器,它是一种让其他程序运行起来的程序。当你编写了一段python程序,python解释器将读取程序,并按照其中
爬虫时如何将网页中的源代码有规律的打印
软件
2024-03-03
python怎么看源码进行网络爬虫
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。 我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。好吧~!其实你很厉害的,右键查看页面源代码。 我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。 一,获取整个页面数据 首先我们可以先获取要下载图片的整个页面信息。 getjpg.py #coding=utf-8 import如何用python写爬虫来获取网页中所有的文章以及关键词
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。
类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源。
在Python中,我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
它以urlopen函数的形式提供了一个非常简单的接口。
最简单的urllib2的应用代码只需要四行。
我们新建一个文件urllib2_test01.py来感受一下urllib2的作用:
import urllib2
response = urllib2.urlopen('http://www.baidu.com/')
html = response.read()
print html
按下F5可以看到运行的结果:
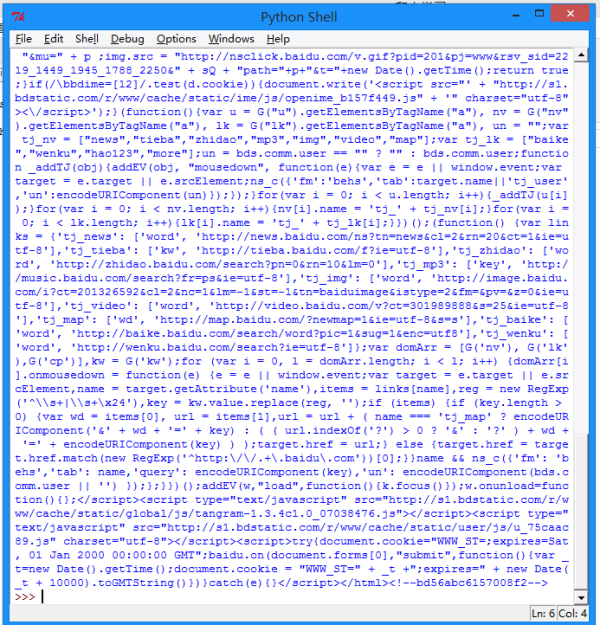
我们可以打开百度主页,右击,选择查看源代码(火狐OR谷歌浏览器均可),会发现也是完全一样的内容。
也就是说,上面这四行代码将我们访问百度时浏览器收到的代码们全部打印了出来。
这就是一个最简单的urllib2的例子。
除了"http:",URL同样可以使用"ftp:","file:"等等来替代。
HTTP是基于请求和应答机制的:
客户端提出请求,服务端提供应答。
urllib2用一个Request对象来映射你提出的HTTP请求。
在它最简单的使用形式中你将用你要请求的地址创建一个Request对象,
通过调用urlopen并传入Request对象,将返回一个相关请求response对象,
这个应答对象如同一个文件对象,所以你可以在Response中调用.read()。
我们新建一个文件urllib2_test02.py来感受一下:
import urllib2
req = urllib2.Request('http://www.baidu.com')
response = urllib2.urlopen(req)
the_page = response.read()
print the_page
可以看到输出的内容和test01是一样的。
urllib2使用相同的接口处理所有的URL头。例如你可以像下面那样创建一个ftp请求。
req = urllib2.Request('ftp://example.com/')
在HTTP请求时,允许你做额外的两件事。
1.发送data表单数据
这个内容相信做过Web端的都不会陌生,
有时候你希望发送一些数据到URL(通常URL与CGI[通用网关接口]脚本,或其他WEB应用程序挂接)。
在HTTP中,这个经常使用熟知的POST请求发送。
这个通常在你提交一个HTML表单时由你的浏览器来做。
并不是所有的POSTs都来源于表单,你能够使用POST提交任意的数据到你自己的程序。
一般的HTML表单,data需要编码成标准形式。然后做为data参数传到Request对象。
编码工作使用urllib的函数而非urllib2。
我们新建一个文件urllib2_test03.py来感受一下:
import urllib
import urllib2
url = 'http://www.someserver.com/register.cgi'
values = {'name' : 'WHY',
'location' : 'SDU',
'language' : 'Python' }
data = urllib.urlencode(values) # 编码工作
req = urllib2.Request(url, data) # 发送请求同时传data表单
response = urllib2.urlopen(req) #接受反馈的信息
the_page = response.read() #读取反馈的内容
如果没有传送data参数,urllib2使用GET方式的请求。
GET和POST请求的不同之处是POST请求通常有"副作用",
它们会由于某种途径改变系统状态(例如提交成堆垃圾到你的门口)。
Data同样可以通过在Get请求的URL本身上面编码来传送。
import urllib2
import urllib
data = {}
data['name'] = 'WHY'
data['location'] = 'SDU'
data['language'] = 'Python'
url_values = urllib.urlencode(data)
print url_values
name=Somebody+Here&language=Python&location=Northampton
url = 'http://www.example.com/example.cgi'
full_url = url + '?' + url_values
data = urllib2.open(full_url)
这样就实现了Data数据的Get传送。
2.设置Headers到http请求
有一些站点不喜欢被程序(非人为访问)访问,或者发送不同版本的内容到不同的浏览器。
默认的urllib2把自己作为“Python-urllib/x.y”(x和y是Python主版本和次版本号,例如Python-urllib/2.7),
这个身份可能会让站点迷惑,或者干脆不工作。
浏览器确认自己身份是通过User-Agent头,当你创建了一个请求对象,你可以给他一个包含头数据的字典。
下面的例子发送跟上面一样的内容,但把自身模拟成Internet Explorer。
(多谢大家的提醒,现在这个Demo已经不可用了,不过原理还是那样的)。
import urllib
import urllib2
url = 'http://www.someserver.com/cgi-bin/register.cgi'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'name' : 'WHY',
'location' : 'SDU',
'language' : 'Python' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
the_page = response.read()
以上就是python利用urllib2通过指定的URL抓取网页内容的全部内容,非常简单吧,希望对大家能有所帮助。
如何爬虫网页数据
爬取网页数据原理如下: 如果把互联网比作蜘蛛网,爬虫就是蜘蛛网上爬行的蜘蛛,网络节点则代表网页。当通过客户端发出任务需求命令时,ip将通过互联网到达终端服务器,找到客户端交代的任务。一个节点是一个网页。蜘蛛通过一个节点后,可以沿着几点连线继续爬行到达下一个节点。 简而言之,爬虫首先需要获得终端服务器的网页,从那里获得网页的源代码,若是源代码中有有用的信息,就在源代码中提取任务所需的信息。然后ip就会将获得的有用信息送回客户端存储,然后再返回,反复频繁访问网页获取信息,直到任务完成。怎么用java写网络爬虫将网页中的指定数据下载到本地excel文档中
mportjava.io.InputStream;
importjava.net.*;
publicclassHelloHttp{
}
接著就可以仿照下列范例建立HTTP连线:
URLurl=newURL("http://tw.yahoo.com");
HttpURLConnectionhttp=(HttpURLConnection)url.openConnection();
http.setRequestMethod("POST");
InputStreaminput=http.getInputStream();
http.disconnect();
第1行建立一个URL物件,带入参数为想要建立HTTP连线的目的地,例如网站的网址。
第2行建立一个HttpURLConnection物件,并利用URL的openConnection()来建立连线。
第3行利用setRequestMethod()来设定连线的方式,一般分为POST及GET两种。
第4行将连线取得的回应载入到一个InputStream中,然後就可以将InputStream的内容取出应用,以这个例子而言我们取得的会是网页的原始码。
第5行用disconnect()将连线关闭。
将InputStream内容取出应用的范例如下:
byte[]data=newbyte[1024];
intidx=input.read(data);
Stringstr=newString(data,0,idx);
System.out.println(str);
input.close();
针对str作regularexpression处理,依照需求取得内容。
如何用用网络爬虫代码爬取任意网站的任意一段文字?
网络爬虫是一种自动化的程序,可以自动地访问网站并抓取网页内容。要用网络爬虫代码爬取任意网站的任意一段文字,可以按照如下步骤进行:
准备工作:需要了解目标网站的结构,以及想要爬取的文字所在的网页的URL。此外,还需要选择一种编程语言,如Python、Java、C++等,一般建议用PYTHON,因为有完善的工具库,并准备好相应的编程环境。
确定目标:通过研究目标网站的结构,确定想要爬取的文字所在的网页的URL。
获取网页源代码:使用编程语言的相应库(如Python的urllib库),访问目标网页的URL,获取网页的源代码。
解析网页源代码:使用编程语言的相应库(如Python的BeautifulSoup库),解析网页源代码,找到想要爬取的文字所在的HTML标签。
提取文字:获取HTML标签的文本内容,即为所要爬取的文字。
保存结果:将爬取的文字保存到文件中或数据库中,以便后续使用。
标签:信息技术 爬虫(计算机网络) python 编程语言 Python入门
相关文章
- 详细阅读
-
用python编程要求输入一个两位数,输详细阅读

用vb编程要求输入一个两位数,输出:个位和十位的和OptionExplicit
PrivateSubCommand1_Click()
DimaAsInteger
Dima1AsInteger
Dima2AsInteger
a=Val(Text1.Text)
Ifa>99O -
用PYTHON写一个自动登录银杏甲天下详细阅读

用python 写一个自动登录网站程序。网址都没有给出怎么测试呢? 这个应该是服务器生成的token吧,可以urllib2抓一下,如果抓不到的话那么他可能用的js动态加载,这个得分析js源码了
-
python算法问题?详细阅读

python算法问题?因为你的代码里每次递归调用fib都重新生成了memo没有起到“备忘录”的作用应该让memo定义在fib外,这样每次递归就可以利用之前已经计算过的结果了具体代码如下
-
Python无法安装某些库详细阅读

Python3.10版 Win1064位无法安装lxml库?在练习xpath时,需要安装lxml模块,报错需要 Microsoft Visual C++ 14.0 吐槽一些教程:pip install wheel,安装无效果的 环境 window 10
-
python cad图块旋转 中心变了详细阅读

cad对象中心旋转具体的没有! 但如果是规则的多边形,可以用"对象追踪及极轴"去捕捉那些虚拟的中心点,可以找到,不要做什么辅助线画的那种,它是CAD程序里自显示出两条虚拟线,
-
python如何在enterbox中创建按钮详细阅读
python脚本如何添加启动和停止按钮?用tkinter的button组件。 设定好字体大小size(int类型),在循环内部(以while举例)加组件: xunhuan=1 # 控制循环的开始与结束 # 定义开始循环 def
-
python爬虫post请求结果返回状态码详细阅读
Python使用requests进行爬虫时返回是怎么回事?如何解决?首先,你用post请求登录了,所以第一个状态码是200,其次,你在第二个get请求里面没有设置cookie值,所以会被禁止访问。修改版如
-
如何将两个不同Python文件的运行生详细阅读

python 如何把多个文件内容合并到以一个文件Python编程将多个文件合并,代码如下:#例子:合并a.txt、b.txt、c.txt合并成d.txt文件#文件列表,遍于读取
flist = ['a.txt','b.txt',' -
怎么让python代码显示彩色的,而不是详细阅读

Python的IDE软件IDLE保存后无彩色,怎样显示彩色(不...sorry,来晚了 python的IDLE显示的‘彩色’,其实是因为有了语法高亮的原因。。。这个还可以设置的 设置路径:Options -> Conf