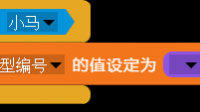
在scratch软件中,怎么设置a角色碰到了b角色的某个造型假如a角色是小马,b是小老虎,首先我们先看看小老虎的代码,在两个碰到了以后,将当前造型编号放到变量当中然后看小马这边就可
flink的standalone集群模式,任务只分配在一个taskmanager上了,其他两个空闲这
软件
2024-05-21
8.一文搞定Flink单作业提交模式(per-job)的运行时状态
在Flink进行数据处理的时候,有两个最重要的两个组件,分别是:作业管理器(JobManager)和任务管理器(TaskManager)。对于一个提交执行的作业,JM是真正的管理者,负责管理和调度工作。如果集群没有配置高可用的话,只能有一个JM。TM是负责工作的工作者,负责执行任务和处理数据,所以可以有很多个。整个JM由三个部分组成,分别是JobMaster、ResourceManager、Dispatcher。
JMaster是JManager中最核心的组件,负责处理单独的作业。所以每一个Job都会有一个对应JobMaster与之对应,多个job可以同时运行在一个FLink集群中,也就证明一个Flink集群中可以有多个JobMaster同时存在。在作业被提交的时候,JMaster会率先接受到要执行的应用。这些应用包括:Jar包、数据流图(dataflow graph)、作业图(JobGraph)。然后将接收到的作业图转换成为一个物理层面的数据流图,也就是执行图,这个执行图包含了所有要并发执行的任务。随后JMaster会根据这个执行图去到RM中申请必要的资源。一旦获得到了足够的资源,就会将执行图发送到要运行执行图的TaskMaster上面。并且在程序运行的过程中,JobMaster会负责协调所有的需要中央协调的工作,如保存点机制。
RM在Flink的集群中只有一个,它主要负责的是资源的分配与管理,也就是对TaskManager上的solt的分配工作。并且在面对不同的环境的时候,RM也有不同的体现。如果是standalone,因为TM是独立运行的,所有RM只能分发可用的TM的任务槽,没办法单独启动TM。但是如果是yarn的工作模式下,RM能够将有空闲的TM发送给JMaster,如果资源不够使用的话,就会向yarn发起请求提供启动TM的容器。并且如果有的TM处于空闲状态,RM还负责停止它们的工作。
它主要负责提供Rest风格的接口来提交应用。并且还负责为每一个新提交的作业启动一个新的JMaster组件,并且还会启动一个WEB UI,方便用来展示和键控作业执行的信息。
TM负责FLink集群中的具体工作部分,数据流的计算就是由这个组件来完成的,每一个TM都会有一定数量的任务槽,这个任务槽是一个TM上最小的资源封装单位,solt的数量决定了TM能够并行处理的任务的数量。在TM启动之后,会向RM注册自己的solt,当收到RM对其发送的指令之后,就会根据要求发送能够提供计算的solt给JMaster调用,这样数据计算就能够实现了,并且在进行计算的过程中,TaskManager可以缓冲数据,还能够与其他的TM交互完成数据的交换。
因为我本人所接触的Flink的部署模式都是基于资源管理平台yarn来实现工作的,采用的作业提交方式也是通过per-job提交方式进行提交的,所以在本次讲述的过程中,也是以这个内容为蓝本展开讲解。
yarn-per-job作业提交流程:
在单作业模式下,Flink集群不会预先启动,而是在进行作业提交的时候,才会启动新的JobManager。
1.客户端向yarn提交作业,并且需要将Flink的Jar包和配置文件信息上传到HDFS,以便后续启动FLink相关组件的容器。
2.YARN资源管理器分配Container资源,启动Application Master,这个APP里面包含了Flink的JobManager,并且要将提交上来的作业交给JMaster。
3.JMaster向flink的rm请求资源。
4.flink的rm向yarn请求container资源。
5.yarn启动包含TM的container资源。
6.TM向JMaster注册自己拥有的solt数量。
7.flink的RM向TM申请solt。
8.TM连接到对应的JMaster,然后通过solt。
9.JMaster将要执行的任务分发给TM,执行。
【Flink on k8s】Flink on Kubernetes 部署模式
Flink 选择 Kubernetes 的主要原因是结合 Flink 和 Kubernetes 的 长稳性 。① Flink 特性 :提供的实时服务是需要 长时间、稳定地运行 ,常应用于电信网络质量监控、实时风控、实时推荐等稳定性要求较高的场景;
② Kubernetes 优势 : 为应用提供了部署、管理能力,同时保证其稳定运行 。Kubernetes 具有很好的生态,可以 集成各种运维工具 ,例如 prometheus、主流日志采集工具等。Kubernetes 具有很好的 扩缩容机制 ,可以大大提高资源利用率。
预先构建 Flink 集群,且该集群长期处于运行状态,但不能自动扩缩容 。用户通过 client 提交作业到运行中的 JobManager,而 JobManager 将任务分配到运行中的 TaskManager。
Flink 集群是预先启动运行的。用户提交作业的时候,作业可以立即分配到 TaskManager,即 作业启动速度快 。
① 资源利用率低 ,提前确定 TaskManager 数量,如果作业需要的资源少,则大量 TaskManager 处于闲置状态。反正 TaskManager 资源不足。
② 作业隔离性差 ,多个作业的任务存在资源竞争,相互影响。如果一个作业异常导致 TaskManager 挂了,该 TaskManager 上的全部作业都会被重启。
参考: Flink on Standalone Kubernetes Reference
① 集群配置
集群配置通过 configmap 挂载到容器中
flink-configuration-configmap.yaml
② Deployment 文件
把 Flink 镜像 上传到 私有镜像仓 。编辑 jobmanager-service.yaml、jobmanager-deployment.yaml、taskmanager-deployment.yaml
jobmanager-deployment.yaml
taskmanager-deployment.yaml
jobmanager-service.yaml
③ 执行 yaml
通过 kubectl create -f 命令创建 Flink 集群
每个作业独占一个 Flink 集群,当作业完成后,集群也会被回收。
一个作业独占一个集群, 作业的隔离性好 。
资源利用率低 ,提前确定 TaskManager 数量,如果作业需要的资源少,则大量 TaskManager 处于闲置状态。反之 TaskManager 资源不足。同时,JobManager 不能复用。
类似 Session 模式,需要 预先构建 JobManager 。不同点是用户通过 Flink Client 向 JobManager 提交作业后, 根据作业需要的 Slot 数量,JobManager 直接向 Kubernetes 申请 TaskManager 资源 ,最后把作业提交到 TaskManager 上。
TaskManager 的资源是实时的、按需进行的创建,对 资源的利用率更高 。
作业真正运行起来的时间较长 ,因为需要等待 TaskManager 创建。
参考: Native Kubernetes - Session Mode
① 集群配置
集群配置通过 configmap 挂载到容器中,如上 2.1 所示。
新增如下配置:
flink-configuration-configmap.yaml
② 配置 jobmanager-deployment.yaml
如上 2.1 所示,需要把启动脚本修改为 ./bin/kubernetes-session.sh
jobmanager-deployment.yaml
③ 执行 yaml
通过 kubectl create -f 命令创建 Flink 集群
类似 Application 模式,每个作业独占一个 Flink 集群,当作业完成后,集群也会被回收。不同点是 Native 特性 ,即 Flink 直接与 Kubernetes 进行通信并 按需申请资源 ,无需用户指定 TaskManager 资源的数量。
① 一个作业独占一个集群,作业的隔离性好。
② 资源利用率相对较高 ,按需申请 JobManager 和 TaskManager。
① 一个作业独占一个集群, JobManager 不能复用 。
② 作业启动较慢 ,在作业提交后,才开始创建 JobManager 和 TaskManager。
Flink on Yarn模式下的TaskManager个数
Flink on YARN支持两种模式,一种是预先在YARN上启动一个long-running的Flink集群,所有的Flink作业都会提交到这个集群中,共享Flink集群资源。另一种模式是单独在YARN上运行单一的Flink 作业,每个作业需要的资源由YARN负责分配。本文总结下第二种模式下的并发配置和TaskManager拉起情况。Parallel的配置有好几种方式,可以配置全局默认参数,可以在client端配置参数,可以配置operator参数等等。由于不是本文讨论的重点,因此可以参考 Flink官网 .
这个参数是配置一个TaskManager有多少个并发的slot数。有两种配置方式:
注意: Per job模式提交作业时并不像session模式能够指定拉起多少个TaskManager,TaskManager的数量是在提交作业时根据并发度动态计算。
首先,根据设定的operator的最大并发度计算,例如,如果作业中operator的最大并发度为10,则 Parallelism/numberOfTaskSlots 为向YARN申请的TaskManager数。
例如:如下作业,Parallelism为10,numberOfTaskSlots为1,则TaskManager为10。
如果numberOfTaskSlots为3,则TaskManager为4.
Apache Flink快速入门-基本架构、核心概念和运行流程
Flink是一个基于流计算的分布式引擎,以前的名字叫stratosphere,从2010年开始在德国一所大学里发起,也是有好几年的 历史 了,2014年来借鉴了社区其它一些项目的理念,快速发展并且进入了Apache顶级孵化器,后来更名为Flink。Flink在德语中是快速和灵敏的意思 ,用来体现流式数据处理速度快和灵活性强等特点。
Flink提供了同时支持高吞吐、低延迟和exactly-once 语义的实时计算能力,另外Flink 还提供了基于流式计算引擎处理批量数据的计算能力,真正意义上实现了流批统一。
Flink 独立于Apache Hadoop,且能在没有任何 Hadoop 依赖的情况下运行。
但是,Flink 可以很好的集成很多 Hadoop 组件,例如 HDFS、YARN 或 HBase。 当与这些组件一起运行时,Flink 可以从 HDFS 读取数据,或写入结果和检查点(checkpoint)/快照(snapshot)数据到 HDFS 。 Flink 还可以通过 YARN 轻松部署,并与 YARN 和 HDFS Kerberos 安全模块集成。
Flink具有先进的架构理念、诸多的优秀特性,以及完善的编程接口。
Flink的具体优势有如下几点:
(1)同时支持高吞吐、低延迟、高性能;
(2)支持事件时间(Event Time)概念;
事件时间的语义使流计算的结果更加精确,尤其在事件到达无序或者延迟的情况下,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。
(3)支持有状态计算;
所谓状态就是在流计算过程中,将算子的中间结果数据保存在内存或者文件系统中,等下一个事件进入算子后,可以从之前的状态中获取中间结果,计算当前的结果,从而无需每次都基于全部的原始数据来统计结果。
(4)支持高度灵活的窗口(Window)操作;
(5)基于轻量级分布式快照(Snapshot)实现的容错;
(6)基于JVM实现独立的内存管理;
(7)Save Points(保存点);
保存点是手动触发的,触发时会将它写入状态后端(State Backends)。Savepoints的实现也是依赖Checkpoint的机制。Flink 程序在执行中会周期性的在worker 节点上进行快照并生成Checkpoint。因为任务恢复的时候只需要最后一个完成的Checkpoint的,所以旧有的Checkpoint会在新的Checkpoint完成时被丢弃。Savepoints和周期性的Checkpoint非常的类似,只是有两个重要的不同。一个是由用户触发,而且不会随着新的Checkpoint生成而被丢弃。
在Flink整个软件架构体系中,统一遵循了分层的架构设计理念,在降低系统耦合度的同时,为上层用户构建Flink应用提供了丰富且友好的接口。
整个Flink的架构体系可以分为三层:
Deployment层: 该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN),云(GCE/EC2),Kubernetes等。
Runtime层:Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层: 主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的计算框架,也分别对应于面向流处理和面向批处理两类。
核心概念:Job Managers,Task Managers,Clients
Flink也是典型的master-slave分布式架构。Flink的运行时,由两种类型的进程组成:
Client: Client不是运行时和程序执行的一部分,它是用来准备和提交数据流到JobManagers。之后,可以断开连接或者保持连接以获取任务的状态信息。
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager, JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。 TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
每个Worker(Task Manager)是一个JVM进程,通常会在单独的线程里执行一个或者多个子任务。为了控制一个Worker能够接受多少个任务,会在Worker上抽象多个Task Slot (至少一个)。
只有一个slot的TaskManager意味着每个任务组运行在一个单独JVM中。 在拥有多个slot的TaskManager上,subtask共用JVM,可以共用TCP连接和心跳消息,同时可以共用一些数据集和数据结构,从而减小任务的开销。
Flink的任务运行其实是多线程的方式,这和MapReduce多JVM进程的方式有很大的区别,Flink能够极大提高CPU使用效率,在多个任务之间通过TaskSlot方式共享系统资源,每个TaskManager中通过管理多个TaskSlot资源池对资源进行有效管理。
Flink on Yarn两种模式启动参数及在Yarn上的恢复
注意:系统和运行脚本在启动时解析配置.对配置文件的更改需要重新启动Flink JobManager和TaskManagersFlink on Yarn模式安装部署要做的其实不多,正常的步骤:
1、上传二进制包 ===》2、解压缩 ===》 3、更改文件名称 ===》 4、配置环境变量。Flink on yarn的job运行模式大致分为两类:
第一种模式分为两步:yarn-session.sh(开辟资源)--->flink run(提交任务)
另外,jobmanager和taskmanager分别占有容器,示例:
./bin/yarn-session.sh -n 10 -tm 8192 -s 32
上面的例子将会启动11个容器(即使仅请求10个容器),因为有一个额外的容器来启动ApplicationMaster 和 job manager,一旦flink在你的yarn集群上部署,它将会显示job manager的连接详细信息。
第二种模式其实也分为两个部分,依然是开辟资源和提交任务,但是在Job模式下,这两步都合成一个命令了。
这里,我们直接执行命令
在job结束后就会关闭flink yarn-session的集群
sudo /usr/lib/flink/bin/flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 -ys 1 -p 1 xz-flink-examples-1.0.jar
• "run" 操作参数:
注意:client必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败。
经试验发现,其实如果配置的有HADOOP_HOME环境变量的话也是可以的。HADOOP_HOME ,YARN_CONF_DIR,HADOOP_CONF_DIR 只要配置的有任何一个即可。
独立job模式客户端命令行参数参考: flink独立Job命令
Flink 的 YARN 客户端具有以下配置参数来控制容器故障时的行为方式。这些参数可以从 conf/flink-conf.yaml 中设置,或者在启动会话时使用-D参数设置
如:
参考: flink中文官网关于参数的解释
相关文章
- 详细阅读
-
大数据云计算好不好学习?详细阅读

大数据云计算好不好学习?你好,很高兴为你解答: 大数据和云计算其实并不难学,学习云计算及大数据需要有java,linux,mysql、python等基础,一般4到5个月的培训就能找工作了。 云计算的
-
windows10编程打开还是原来界面怎详细阅读

我的win10开始界面编程这样了,求大神告知怎么修改回正常的样子您可以打开开始菜单,点击“设置”,在弹出的页面中点击“个性化”,选择“开始”选项卡,将“使用全屏幕开始菜单”项
-
找一位java编程高手,编写一个简单的详细阅读
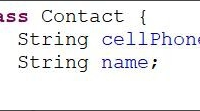
JAVA通讯录 求一个JAVA编写的通讯录,基本的就可以。具体方法如下:1、定义封装一条记录的实体类2、根据实际系统容量,定义一个数组3、完成系统中显示全部记录的逻辑4、完成系统
- 详细阅读
-
求大神帮忙,这个怎么编程,或者怎么用详细阅读
求excel大神帮忙录制个宏或者用公式实现下面的问题非常高兴为您解答问题,其实您这个问题不用录制宏,当排完序后,设置一个公式就可以了。还没有想到更好的办法,需要加一列进行辅
- 详细阅读
-
辽宁省干部在线学习网:显示“系统繁详细阅读

2022辽宁省干部在线学习网登录不上2022辽宁省干部在线学习网登录不上先确定学信网账户是否已经开通,账号、密码、验证码是否正确。如果上面两个都没什么问题,还是登不上可以播
-
C++编程答题遇到问题-图灵编程(求助详细阅读
求答案,c语言C++和java都是后来出现的,都不是纯OO,第一个纯OO语言是1972年出现的Smalltalk。 诸如“对象”和“对象的属性”这样的概念,可以一直追溯到1950年代初。它们首先出
-
编程题8255芯片中的灯泡题他的取反详细阅读
单片机 思考题与习题 急 谢谢。。。。1、分4组,分别由PSW中RS1、RS0控制,每组8个单元,复位后的寄存器是第0组。能被8整除的都可以进行位寻址。EA:片内外程序存储器片选端,ALE:

