如何下载python?1、打开python官网。 2、找到python的下载页面,可以看到有多个版本可选择,要注意3.x版跟旧版本并不兼容。选择最新发布的正式版3.8.2。 3、windows版的安装包
中文代码绘图板能运行py文件吗
软件
2024-08-10
python怎么运行py文件
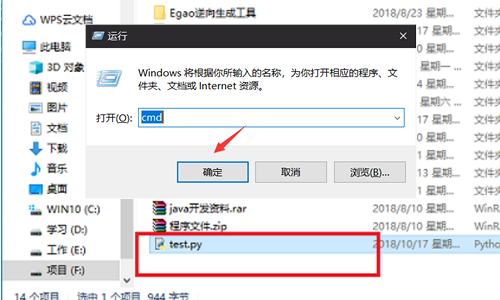
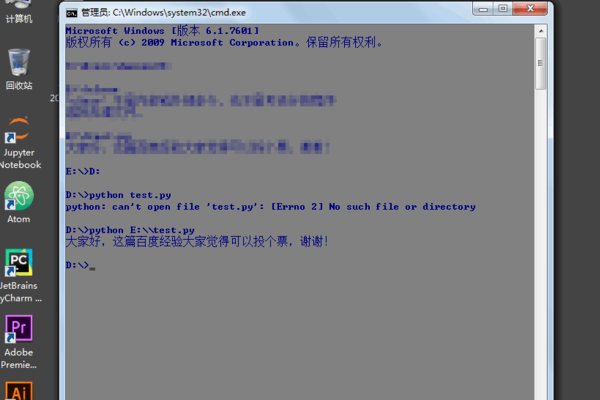
1、首先在资源管理器里复制一下py文件存放的路径,按下windows键+r,在运行里输入cmd,回车打开命令行:
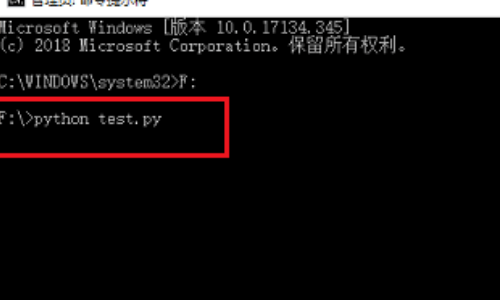
2、在命令行里,先切换到py文件的路径下面,接着输入“python 文件名.py”运行python文件:
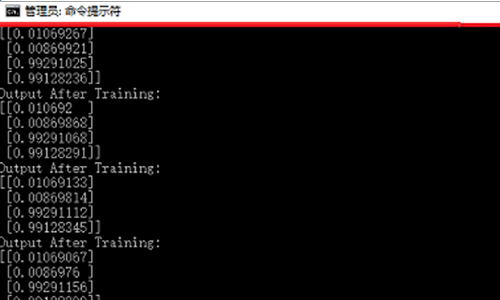
3、按下回车键,可以看到窗口中py文件开始运行了,注意在命令行运行py文件,要将python安装路径添加到环境变量path中,否则会报错,找不到命令。至此python运行文件的操作就完成了:
后缀PY的文件怎么用?
后缀PY的文件可以用Python软件打开,具体操作步骤如下:
1、首先确定一下我们要打开的PY文档在哪里。
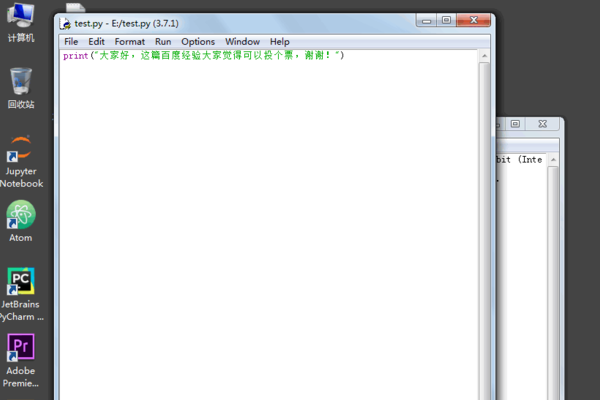
2、打开cmd,cd到该目录下,输入文件名,比如test.py,回车后就可以运行文件了。
3、如果没有在目录下,那么我们要输入具体地址来执行。

4、还有一个方法就是直接把PY文档拖动进入窗口,ENTER就可以执行了。
pycharm怎么运行py文件
pycharm运行py文件的方法:在代码区域右键点击【Run '文件名'】即可运行代码。
pyahcrm写好的python代码后在空白位置右键点击run即可。使用 PyCharm Community Edition 2019.1 版本,该版本免费且可在所有主流平台上使用。只有最后一部分「PyCharm Professional 功能」使用的是 PyCharm Professional Edition 2019.1 版本。
含义
推荐使用 JetBrains Toolbox App 安装PyCharm。使用该 App,你可以安装不同的 JetBrains 产品或者同一产品的不同版本,并在必要的情况下更新、回滚和轻松删除任意工具。你还可以在恰当的 IDE 及版本中快速打开任意项目。
python怎么运行py文件?
在如何使用Python脚本转换数据和命令行中,我们将深入探讨如何使用Python脚本和命令行来转换数据。
但是首先,值得提出一个您可能正在思考的问题:“Python如何适合命令行,为什么当我知道我可以使用IPython笔记本完成所有数据科学工作时,为什么还要使用命令行与Python进行交互?还是Jupyter实验室?”
笔记本非常适合快速进行数据可视化和探索,但是Python脚本是将我们学到的东西投入生产的一种方式。假设您想建立一个网站,以帮助人们发布具有理想标题和提交时间的HackerNews帖子。为此,您需要脚本。
本教程假定您具有函数的基本知识,并且有一点命令行经验也不会受到损害。如果您以前从未使用过Python,请随时查看我们涵盖Python函数基础的任务,或者更深入地研究我们的一些数据科学课程。最近,我们发布了两个新的交互式命令行课程:“命令行元素”和“命令行中的文本处理”,因此如果您想更深入地研究命令行,我们也建议您
也就是说,不必过分担心先决条件!我们将解释我们正在做的所有事情,所以让我们开始吧!
熟悉数据
HackerNews是一个站点,用户可以在该站点上通过Internet(通常是有关技术和创业公司)提交文章,而其他人可以“赞扬”这些文章,表示他们喜欢它们。提交的投票越多,在社区中就越受欢迎。热门文章进入HackerNews的“首页”,在其他网站上它们更有可能被他人看到。
我们将使用的数据集是由ArnaudDrizard使用HackerNewsAPI编译的,可以在此处找到。我们从数据中随机抽取了10000行,并删除了所有多余的列。我们的数据集只有四列:
submission_time-故事提交时。
upvotes-提交的投票数。
url—提交的基本域。
headline—提交的标题。用户可以对其进行编辑,而不必与原始文章的标题相匹配。
我们将编写脚本来回答三个关键问题:
哪些新闻最常出现在头条新闻中?
哪些域名最常提交给HackerNews?
大多数文章什么时候提交?
切记:在编程时,有多种方法可以处理任务。在本教程中,我们将逐步解决这些问题,但是肯定还有其他方法同样有效,因此请随时尝试并尝试提出自己的方法!
使用命令行和Python脚本读取数据
要加注星标,让我们Transforming_Data_with_Python在桌面上创建一个文件夹。要使用命令行创建文件夹,可以使用mkdir命令,后跟文件夹名称。例如,如果要创建一个名为的文件夹test,则可以导航到Desktop目录,然后键入mkdirtest。
我们将稍后讨论为什么创建文件夹,但是现在,让我们使用cd命令导航到创建的文件夹。该cd命令允许我们使用命令行更改目录。
尽管有多种使用命令行创建文件的方法,但我们可以利用一种称为管道传输和重定向输出的技术来一次完成两件事:将输出从stdout(命令行生成的标准输出)重定向到文件中并创建一个新文件!换句话说,我们可以让它创建一个新文件并使它的输出成为该文件的内容,而不是让命令行仅打印其输出。
要做到这一点,我们可以使用>和>>,这取决于我们想用文件来完成。如果文件不存在,两者都会创建一个文件;但是,>将使用重定向的输出覆盖文件中已有的文本,同时>>将任何重定向的输出附加到文件中。
我们希望将数据读入该文件并创建一个描述性的文件名和函数名称,因此我们将创建一个名为的函数,load_data()并将其保存在名为的文件中read.py。让我们使用读取数据的命令行创建函数。为此,我们将使用该printf函数。(我们将使用printf它,因为它允许我们打印换行符和制表符,我们将使用它们来使脚本对自己和其他人更具可读性)。
为此,我们可以在命令行中输入以下内容
printf\"importpandasaspddefload_data():hn_stories=pd.read_csv('hn_stories.csv')hn_stories.colummns=['submission_time','upvotes','url','headline']return(hn_stores)\">read.py
检查上面的代码,有很多事情要做。让我们将其分解。在函数中,我们是:
a.请记住,我们要使脚本可读,我们正在使用printf命令通过命令行生成一些输出,以在生成输出时保留格式。
b.进口大熊猫。
c.将数据集(hn_stories.csv)读入pandas数据框。
d.使用df.columns列名添加到我们的数据帧。
e.创建一个名为的函数load_data(),其中包含用于读取和处理数据集的代码。
f.利用换行符()和制表符( )保留格式,因此Python可以读取脚本。
g.将输出重定向printf到read.py使用>运算符调用的文件。由于read.py尚不存在,因此已创建文件。
运行上面的代码后,我们可以catread.py在命令行中键入并执行命令以检查的内容read.py。如果一切正常运行,我们的read.py文件将如下所示:
创造__init__.py
在该项目的其余部分,我们将创建更多脚本来回答我们的问题并使用该load_data()函数。尽管我们可以将该函数粘贴到使用该函数的每个文件中,但是如果我们正在处理的项目很大,则可能会变得非常麻烦。
为了解决这个问题,我们可以创建一个名为的文件__init__.py。本质上,__init__.py允许文件夹将其目录文件视为包。最简单的形式__init__.py可以是一个空文件。它只需要存在就可以将目录文件视为包。您可以在Python文档中找到有关包和模块的更多信息。
因为load_data()是中的函数read.py,所以我们可以使用导入包的相同方法来导入该函数:fromreadimportload_data()。
还记得使用命令行创建文件的多种方法吗?我们可以使用另一个命令来创建文件__init__.py这次,我们将使用该touch命令来创建文件。touch是一个在您运行命令后立即为您创建一个空文件的命令:
探索标题中的单词
现在,我们已经创建了一个脚本来读取和处理数据以及创建的数据__init__.py,我们可以开始分析数据了!我们要探索的第一件事是标题中出现的独特词。为此,我们要执行以下操作:
1)count.py使用命令行创建一个名为的文件。
2)load_data从导入read.py,并调用函数以读取数据集。
3)将所有标题合并为一个长长的字符串。当您合并标题时,我们希望在每个标题之间留一个空格。在此步骤中,我们将使用Series.str.cat连接字符串。
4)将长字符串拆分成单词。
5)使用Counter类可以计算每个单词在字符串中出现的次数。
6)使用该.most_common()方法将100个最常用的单词存储到wordCount。
如果使用命令行创建此文件,则外观如下:
printf\"fromreadimportload_datafromcollectionsimportCounterstories=load_data()headlines=stories['headline'].str.cat(sep='').lower()wordCount=Counter(headlines.split('')).most_common(100)print(wordCount)\">count.py
运行上面的代码后,您可以catcount.py在命令行中键入并执行命令以检查的内容count.py。如果一切正常运行,您的count.py文件将如下所示:
现在,我们已经创建了Python脚本,我们可以从命令行运行脚本以获取一百个最常用单词的列表。要运行脚本,我们从命令行键入pythoncount.py命令。
脚本运行后,您将看到以下打印结果:
[('the',2045),('to',1641),('a',1276),('of',1170),('for',1140),('in',1036),('and',936),('',733),('is',620),('on',568),('hn:',537),('with',537),('how',526),('-',487),('your',480),('you',392),('ask',371),('from',310),('new',304),('google',303),('why',262),('what',258),('an',243),('are',223),('by',219),('at',213),('show',205),('web',192),('it',192),('_',184),('do',183),('app',178),('i',173),('as',161),('not',160),('that',160),('data',157),('about',154),('be',154),('facebook',150),('startup',147),('my',131),('|',127),('using',125),('free',125),('online',123),('apple',123),('get',122),('can',115),('open',114),('will',112),('android',110),('this',110),('out',109),('we',106),('its',102),('now',101),('best',101),('up',100),('code',98),('have',97),('or',96),('one',95),('more',93),('first',93),('all',93),('software',93),('make',92),('iphone',91),('twitter',91),('should',91),('video',90),('social',89),('&',88),('internet',88),('us',88),('mobile',88),('use',86),('has',84),('just',80),('world',79),('design',79),('business',79),('5',78),('apps',77),('source',77),('cloud',76),('into',76),('api',75),('top',74),('tech',73),('javascript',73),('like',72),('programming',72),('windows',72),('when',71),('ios',70),('live',69),('future',69),('most',68)]
在我们的网站上滚动浏览它们会有些尴尬,但是您可能会注意到最常见的词,例如等等。这些词被称为停用词the,toafor这些词对人类语音很有用,但对数据分析没有任何帮助。您可以在我们的spaCy教程中找到更多有关停用词的信息;如果要扩展此项目,则从我们的分析中删除停用词将是一个有趣的下一步。
即使包含了停用词,我们也可以发现一些趋势。除了停用词之外,这些词中的绝大多数都是与技术和创业相关的术语。考虑到HackerNews专注于科技创业公司,这并不奇怪,但是我们可以看到一些有趣的特定趋势。例如,谷歌是该数据集中最常提及的品牌。Facebook,Apple和Twitter等其他品牌也是讨论的热门话题。
探索域提交
现在我们已经探索了不同的标题并显示了前100个最常用的词,现在我们可以探索域提交了!为此,我们可以执行以下操作:
1)domains.py使用命令行创建一个名为的文件。
2)load_data从导入read.py,并调用函数以读取数据集。
3)使用value_counts()大熊猫中的方法来计算列中每个值的出现次数。
4)遍历该系列并打印索引值及其关联的总数。
这是命令行形式的外观:
printf\"fromreadimportload_datastories=load_data()domains=stories['url'].value_counts()forname,rowindomains.items():print('{0}:{1}'.format(name,row))\">domains.py
再一次,如果我们catdomains.py在命令行中输入来检查domains.py,我们应该看到:
探索提交时间
我们想知道大多数文章何时提交。一种简单的重组方法是查看文章的提交时间。为了弄清楚这一点,我们需要使用该submission_time列。
该submission_time列包含如下时间戳:2011-11-09T21:56:22Z。这些时间以UTC表示,UTC是大多数软件用于保持一致性的通用时区(想象一个数据库中填充的时间都具有不同的时区;要使用它会非常麻烦)。
要从时间戳获取小时,我们可以使用该dateutil库。中的parser模块dateutil包含parse函数,该函数可以带一个时间戳,如何使用Python脚本转换数据和命令行并返回一个datetime对象。这是文档的链接。解析时间戳后,hour结果日期对象的属性将告诉您文章提交的时间。
为此,我们可以执行以下操作:
1)times.py使用命令行创建一个名为的文件。
2)编写一个函数以从时间戳中提取小时。此函数应首先用于dateutil.parser.parse解析时间戳,然后从结果datetime对象中提取小时,然后使用来返回小时.hour。
3)使用pandasapply()方法创建提交时间列。
4)使用value_counts()大熊猫中的方法来计算每小时发生的次数。
5)打印结果。
我们在命令行中执行以下操作:
printf\"fromdateutil.parserimportparsefromreadimportload_datadefextract_hour(timestamp):datetime=parse(timestamp)hour=datetime.hourreturnhourstories=load_data()stories['hour']=stories['submission_time'].apply(extract_hour)time=stories['hour'].value_counts()print(time)\">times.py
这是它看起来像一个单独.py文件的样子(如上所述,您可以通过cattimes.py从命令行运行以检查文件来进行确认):
现在,我们已经创建了Python脚本,我们可以从命令行运行脚本,以获取特定时间内发布了多少篇文章的列表。为此,您可以从命令行键入pythontimes.py命令。运行此脚本,您将看到以下结果:
您会注意到大多数提交内容是在下午发布的。但是请记住,这些时间是UTC时间。如果您有兴趣扩展此项目,请尝试在脚本中添加一个部分,以将UTC的输出转换为本地时区。
下一步
在如何使用Python脚本转换数据和命令行中,我们探索了数据并建立了一个短脚本目录,这些短脚本可相互配合以提供所需的答案。这是构建我们的数据分析项目的生产版本的第一步。
但是,当然,这仅仅是开始!在如何使用Python脚本转换数据和命令行中,我们没有使用过upvotes数据,因此这是扩展分析范围的一个不错的下一步:
a.标题长度最大才能获得最多投票?
b.提交时间最多的是什么?
c.投票总数随时间变化如何?
我们鼓励您结合自己的问题,并在继续探索此数据集时发挥创造力!
/i6831049808313057804/
1、首先在资源管理器里复制一下py文件存放的路径,按下windows键+r,在运行里输入cmd,回车打开命令行:
2、在命令行里,先切换到py文件的路径下面,接着输入“python文件名.py”运行python文件:
3、按下回车键,可以看到窗口中py文件开始运行了,注意在命令行运行py文件,要将python安装路径添加到环境变量path中,否则会报错,找不到命令。至此python运行文件的操作就完成了:
.py文件是什么?
.py文件是python的脚本文件。
Python在执行时,首先会将.py文件中的源代码编译成Python的byte code(字节码),然后再由Python Virtual Machine(Python虚拟机)来执行这些编译好的byte code。这种机制的基本思想跟Java,.NET是一致的。
然而,Python Virtual Machine与Java或.NET的Virtual Machine不同的是,Python的Virtual Machine是一种更高级的Virtual Machine。
这里的高级并不是通常意义上的高级,不是说Python的Virtual Machine比Java或.NET的功能更强大,而是说和Java 或.NET相比,Python的Virtual Machine距离真实机器的距离更远。
或者可以这么说,Python的Virtual Machine是一种抽象层次更高的Virtual Machine。基于C的Python编译出的字节码文件,通常是.pyc格式。
扩展资料:
python的优点:
1、简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
2、易学:Python极其容易上手,因为Python有极其简单的说明文档。
3、速度快:Python 的底层是用 C 语言写的,很多标准库和第三方库也都是用 C 写的,运行速度非常快。
4、免费、开源:Python是FLOSS(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。
5、高层语言:用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
6、可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。
7、解释性:一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。
运行程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行 程序。
在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。这使得使用Python更加简单。也使得Python程序更加易于移植。
8、面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。
9、可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。
10、可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
11、丰富的库:Python标准库确实很庞大。它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。
12、规范的代码:Python采用强制缩进的方式使得代码具有较好可读性。而Python语言写的程序不需要编译成二进制代码。
参考资料来源:百度百科-python
标签:Python入门 信息技术 python 操作系统 PyCharm
相关文章
- 详细阅读
-
最近准备学编程,是学C++还是python详细阅读

学编程,学C好还是学Python好?每种编程语言都可以找到他们最强的优势。我们比较的是哪个语言更适合入门学习,选择好一门语言去学习,可以跨越从入门到放弃,避免在学会之前就消耗掉
-
__author__ = 'marble_xu'在pychar详细阅读

pycharm怎么批量注释代码pycharm批量注释代码的方法:首先打开文件,选中需要批量注释的代码;然后按下键盘上的【ctrl+/】快捷键,这样代码就被批量注释了。如果要取消注释,再次按下
-
免费的视频格式转换器或视频格式转详细阅读
免费的电脑视频剪辑软件有哪些?电脑上剪辑视频的免费软件一般是很少的,但基本上都是可以通过安装破解版而达到免费的效果,下面列举几种常用的免费视频剪辑软件: 1、pr。这是一款
-
安装ps您的浏览器或操作系统不再受详细阅读

安装ps时提示浏览器或操作系统不再受支持,如何解决?只能降低版本,重新安装,否则无法正常使用的,因为软件具有兼容性问题,最高版本问题会很多。Adobe Photoshop,简称“PS”,是由Adob
-
杭州壹齐互联信息技术有限公司详细阅读

张杰的个人资料【个人简介】 英文名:Jason 昵称:张小杰、包子、小白、杰宝 小杰 性别:男 民族:汉族 籍贯:中国四川省成都市新都区新繁镇 生日:1982年12月20日 星座:射手座 身高:180C
-
ps2022中文破解版 v23.1.0.143需要详细阅读

ps2022版本对电脑配置要求
ps 2022电脑配置要求
处理器:支持 64 位的 Intel 处理器;具有 SSE 4.2 或更高版本的 2 GHz 或更快的处理器
操作系统:macOS Catalina(版本 10.15)或更 -
请问有谁知道云南机场集团的信息技详细阅读

请问昆明长水机场信息技术员招聘笔试内容考什么?面试又涉及哪些内容呢笔试全是选择题,公共基础(跟事业单位考得差不多)50个单选,专业知识:80个单选,涉及计算机基础,计算机网络,操作系
-
Python与C语言的功能有什么区别详细阅读

c语言和python区别c++和python区别有:作用不同。1、c++为编译型语言,python为解释型的脚本语言。2、c++效率高,编程难;python效率低,编程简单。python一两句代码就搞定的东西,c++
-
pycharm破解方法详细阅读
pycharm专业版能破解吗?pycharm软件+破解免费下载链接:https://pan.baidu.com/s/1PoFCDDykf7Q601vni42vug 提取码:lfhc PyCharm是一种PythonIDE(Integrated Development Envi