
用什么软件能批量修改图片大小呢?批量修改图片磁村大小的方法:步骤1,先下载上面的工具软件然后安装打开,软件界面左边有5个功能,点击中间的【更改尺寸】。然后再点击【添加文件
Python怎么获取Chrome浏览器控制台console的数据
软件
2023-03-30
如何用python获取websocket数据
这里,介绍如何使用 Python 与前端 js 进行通信。 websocket 使用 HTTP 协议完成握手之后,不通过 HTTP 直接进行 websocket 通信。 于是,使用 websocket 大致两个步骤:使用 HTTP 握手,通信。 js 处理 websocket 要使用 ws 模块; python 处理则使用 socket 模块建立 TCP 连接即可,比一般的 socket ,只多一个握手以及数据处理的步骤。 握手 过程 包格式 js 客户端先向服务器端 python 发送握手包,格式如下: ? 1 2 3 4 5 6 7 8 GET /chat HTTP/1.1 Host: s怎样使用Python调用我们平时使用的chrome浏览器
importunittest,os,time
fromseleniumimportwebdriver
fromselenium.common.exceptionsimportNoSuchElementException
dictInput={}
classTest(unittest.TestCase):
defsetUp(self):
self.chromedriver="C:\Users\xxx\AppData\Local\Google\Chrome\Application\chromedriver.exe"#将chromedriver.exe拷贝到你想要调用的chrome安装路径下即可
os.environ["webdriver.chrome.driver"]=self.chromedriver
self.browser=webdriver.Chrome(self.chromedriver)
deftest(self):
self.browser.get('xxxx')#此处xxxx为网页的url
if__name__=='__main__':
importsys;sys.argv=['',
'Test.test'
]
unittest.main()
浏览器F12的Network选项里的数据,使用Python编程如何导出?
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的。所以也就引出了什么是动态数据的概念,动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到浏览器后动态生成的,而之前并没有的。
在编写爬虫进行网页数据抓取的时候,经常会遇到这种需要动态加载数据的HTML网页,如果还是直接从网页上抓取那么将无法获得任何数据。
今天,我们就在这里简单聊一聊如何用python来抓取页面中的JS动态加载的数据。
给出一个网页:豆瓣电影排行榜,其中的所有电影信息都是动态加载的。我们无法直接从页面中获得每个电影的信息。
如下图所示,我们无法在HTML中找到对应的电影信息。
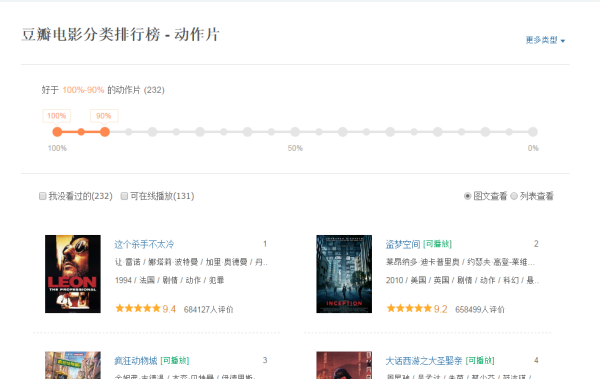
在Chrome浏览器中,点击F12,打开Network中的XHR,我们来抓取对应的js文件来进行解析。如下图:

在豆瓣页面向下拖拽,使得页面加载入更多的电影信息,从而我们可以抓取对应的报文。
我们可以看到它采用的是AJAX异步请求。通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。因此就可以在不重新加载整个网页的情况下,对网页的某部分进行更新,从而实现数据的动态载入。
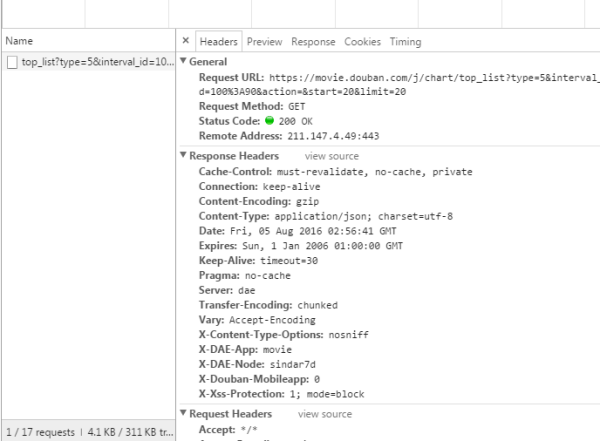
我们可以看到,通过GET,我们得到的response之中包含了所对应的电影相关信息,它们以JSON的格式保存在一起。

查看一下RequestURL信息,我们可以发现在action参数之后又跟了两个参数"start"和"limit",很显然它们的意思是:"从某个位置开始返回的电影的个数"。
如果想快速获取相关的电影信息,就可以直接把这个URL复制进地址栏,修改你所需要的start和limit参数值,将得到对应的结果进行抓取即可。
但是这样显得很不自动化,而且很多其他网站的RequestURL并不给的这么直接,所以我们接下来用python进行进一步的操作来获取这个返回的报文信息。
#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90",data =post_param, verify = False)print return_data.text
因为豆瓣是https的,所以我们在此处需要稍微注意一下,将verify置为False表示不需要验证SSL证书。
我们可以发现打印出的结果中就是对应的JSON文件,下一步的解析和操作在这里就不赘述了。[{"rating":["9.6","50"],"rank":1,"cover_url":"https://img3.doubanio.com\/view\/movie_poster_cover\/mpst\/public\/p480747492.jpg","is_playable":true,"id":"1292052","types":["犯罪","剧情"],"regions":["美国"],"title":"肖申克的救赎","url":"https:\/\/movie.douban.com\/subject\/1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count":713205,"score":"9.6","actors":["蒂姆·罗宾斯","摩根·弗里曼","鲍勃·冈顿","威廉姆·赛德勒","克兰西·布朗","吉尔·贝罗斯","马克·罗斯顿","詹姆斯·惠特摩","杰弗里·德曼","拉里·布兰登伯格","尼尔·吉恩托利","布赖恩·利比","大卫·普罗瓦尔","约瑟夫·劳格诺","祖德·塞克利拉"],"is_watched":false}]
怎么用Python获取Chrome的地址栏句柄
首先,假设通过Firefox()浏览器定向爬取CSDN首页导航栏信息,审查元素代码如下图所示,在div class="menu"路径的ul、li、a下,同时可以定位ul class="clearfix"。 代码如下所示: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # coding=utf-8 import os from selenium import webdriver #PhantomJS无界面浏览器 ##driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windo如何用Python获取浏览器中已打开的网页内容
使用selenium的chrome或firefox的webdriver打开浏览器 driver.get(url) #访问你的网页 from=driver.find_elements_by_xpath("xxx") 通过xpath或id等方法锁定到网页上表单的那个元素后,用 from.send_keys("xxx")标签:python Python入门 信息技术 谷歌(Google) 工具
相关文章
- 详细阅读
- 详细阅读
-
python 判断图片是黑白还是彩色,并详细阅读

如何用python将文件夹中图片根据颜色分类
本文实例讲述了Python通过PIL获取图片主要颜色并和颜色库进行对比的方法。分享给大家供大家参考。具体分析如下:这段代码主要用来从 - 详细阅读
-
自媒体运营有哪些常用的工具?详细阅读

自媒体工具都有哪些?这个问题挺大的,需要分解来说,比如做图文自媒体跟视频自媒体、音频自媒体所需要的工具肯定不同,简单说说: 1、排版工具 帮助我们优化排版效果,非常多,找一个自
- 详细阅读
-
python怎么做接口之间的关联详细阅读

python使用request库怎么关联接口打开命令提示符 Python34换成你的python所在目录 cd C:\Python34\Scriptspip install requestspython多接口有依赖如何调用方法如下:
1. 对 -
图悦-在线词频分析工具不能使用了详细阅读

有没有好用的词云工具,就是可以提取一大段文本的高频词,可以随意排列的那种?如果文字很多,并且需要提取高频词的话,目前有两个词云在线生成器比较合适实现上述功能.第一个就是微
-
python程序设计,里面的txt文件没法详细阅读

使用python编程,实现对文件夹中所有txt文件中的某一列数据都加1?import os
path = r'C:\Users\shinelon\Desktop\新建文件夹' # 替换你的文件夹
path_result = path+"\结果"
l -
有没有大佬知道这是怎么回事?python详细阅读

python安装不了?安装不了是因为禁用了 windows 的第三方安装
解决方法一: 1、在运行里输入gpedit.msc; 2、计算机配置管理>>管理模板>>windows组件>>windows Installer>


